
This tutorial is part of a series on Simultaneous Localization and Mapping (SLAM) using the extended Kalman filter. See the following for other tutorials in the series:
- Introduction
- Step 0: Introducing the Dataset
- Step 1: Localization With Known Correlation
- Step 3: SLAM With Known Correlation
- Step 4: SLAM With Unknown Correlation
This tutorial will build incrementally on the previous tutorial: Localization With Known Correlation. We’re still just doing localization, which means the robot starts with a map of landmarks that does not change over the course of its run. The difference is this time when the robot gets a range and bearing measurement, it will not know to which landmark that measurement corresponds.
In this tutorial I will explain the process for estimating the correspondence between measurements and landmarks and present the correspondence algorithm on its own. Then I will show how the correspondence estimation algorithm can be integrated with the EKF localization algorithm introduced in the prior tutorial. As before, we’ll be using the UTIAS dataset for demonstration purposes.
Measurement Correspondence Intro
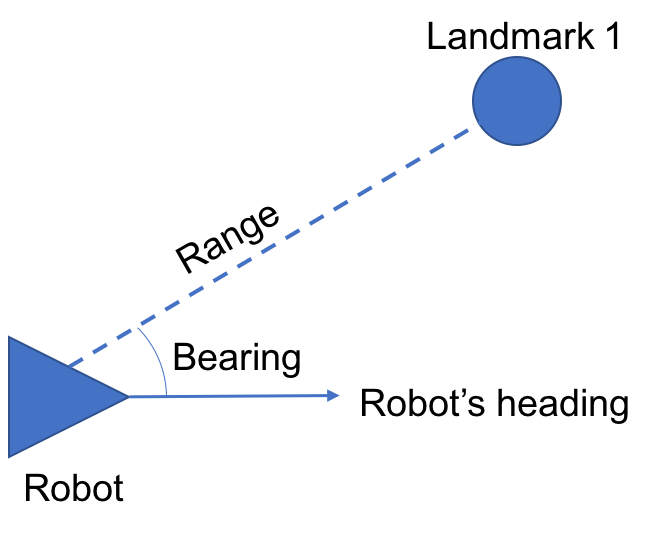
When our robot gets a measurement to a nearby landmark it can use that information to refine its estimate of its pose. In the last tutorial, each measurement received by our robot was in the form of ![z_t^i = [r_t^i\ \phi_t^i\ s_t^i]^T](https://i0.wp.com/andrewjkramer.net/wp-content/ql-cache/quicklatex.com-2748ddc649f7f00566bd0e4f698c3cd3_l3.png?resize=114%2C20&ssl=1 "Rendered by QuickLaTeX.com") where
where  is the measurement to landmark
is the measurement to landmark  at time
at time  . This vector contains the range
. This vector contains the range  , bearing
, bearing  , and, crucially, identity of the landmark being measured
, and, crucially, identity of the landmark being measured  . This could be interpreted as “landmark
. This could be interpreted as “landmark  is
is  meters away, at a bearing of
meters away, at a bearing of  radians.”
radians.”
In our current problem, the measurement vector will be ![z_t^i=[r_t^i\ \phi_t^i]^T](https://i0.wp.com/andrewjkramer.net/wp-content/ql-cache/quicklatex.com-5c2c2413b6a0bc6a72e04a501e2ac888_l3.png?resize=94%2C20&ssl=1 "Rendered by QuickLaTeX.com") . So we are no longer directly telling the robot to which landmark each measurement corresponds. Without knowledge of this correspondence measurements are basically useless to our robot. Sure, it knows the location of a landmark relative to its own location. But without knowing where that landmark is in the world it can’t use that information to refine its estimate of its pose.
. So we are no longer directly telling the robot to which landmark each measurement corresponds. Without knowledge of this correspondence measurements are basically useless to our robot. Sure, it knows the location of a landmark relative to its own location. But without knowing where that landmark is in the world it can’t use that information to refine its estimate of its pose.
So our robot needs a way to estimate the correspondence between its measurements and the landmarks in its map. One way it can do this is through maximum likelihood data association.
Maximum Likelihood Data Association
In maximum likelihood data association, as presented in section 7.5.2 of Probabilistic Robotics, the robot computes the probability that its current measurement corresponds to every landmark in its map. It then chooses the landmark with the highest probability of correspondence and assumes it is the correct association. This can be written as

In other words, given the robot’s past measurement correspondences  , map
, map  , past measurements
, past measurements  , and past control inputs
, and past control inputs  , which landmark has the highest probability of producing measurement
, which landmark has the highest probability of producing measurement  ?
?
In practice we find this by calculating the expected measurement and measurement covariance for every landmark in the map. We can then use these to calculate the measurement probability for every landmark and then select the landmark with the highest probability. The algorithm goes as follows:
![\begin{align*} \text{for all}&\text{ measurements } z_t^i=[r_t^i\ \phi_t^i]^T \text{ do} \\ \text{for}&\text{ all landmarks } k \text{ in the map } m \text{ do} \\ &q = (m_{k,x} - \bar{\mu}_{t,x})^2 + (m_{k,y} - \bar{\mu}_{t,y})^2 \\ &\hat{z}_t^k = \begin{bmatrix} \sqrt{q} \\ \text{atan2}(m_{k,y}-\bar{\mu}_{t,y},\ m_{k,x}-\bar{\mu}_{t,x})-\bar{\mu}_{t,\theta} \end{bmatrix} \\ &H_t^k = \begin{bmatrix} -\frac{m_{k,x}-\bar{\mu}_{t,x}}{\sqrt{q}} & -\frac{m_{k,y}-\bar{\mu}_{t,y}}{\sqrt{q}} & 0 \\ \frac{m_{k,y}-\bar{\mu}_{t,y}}{q} & -\frac{m_{k,x}-\bar{\mu}_{t,x}}{q} & -1\end{bmatrix} \\ &S_t^k = H_t^k \bar{\Sigma}_t [H_t^k]^T + Q_t \\ \text{end}&\text{for} \\ j(i) &= \text{argmax}_k\ \text{det}(2\pi S_t^k)^{-\frac{1}{2}} \text{exp}\{-\frac{1}{2}(z_t^i-\hat{z}_t^k)[S_t^k]^{-1}(z_t^i-\hat{z}_t^k)^T\}\\ \text{endfor}& \end{align*}](https://i0.wp.com/andrewjkramer.net/wp-content/ql-cache/quicklatex.com-64e1846930d8c3fb71680afa0184f6e8_l3.png?resize=509%2C311&ssl=1 "Rendered by QuickLaTeX.com")
The end result  is the estimated correspondence
is the estimated correspondence  for each measurement . It should be noted that the probability estimates are conditioned on past correspondences. However, this method assumes that the past estimates are correct. This means that the correspondence estimates are very sensitive to incorrect associations; incorrect estimates are likely to remain incorrect on subsequent measurements. This makes the maximum likelihood method brittle and likely to diverge when measurements are incorrectly associated.
for each measurement . It should be noted that the probability estimates are conditioned on past correspondences. However, this method assumes that the past estimates are correct. This means that the correspondence estimates are very sensitive to incorrect associations; incorrect estimates are likely to remain incorrect on subsequent measurements. This makes the maximum likelihood method brittle and likely to diverge when measurements are incorrectly associated.
There are alternative methods that are more robust to incorrect associations. Multi-Hypothesis Tracking is one of these, but the maximum likelihood method is the simplest. For an introduction I think the maximum likelihood method is sufficient.
The Complete Algorithm
The code for the complete algorithm is shown below. It is the same as the code for EKF localization with known correlation with the addition of the maximum likelihood algorithm for measurement correspondence (lines 85 to 120). Note also that the code rendering program I’m using doesn’t seem to handle MATLAB code very well, and some of the highlighting is a little messed up.
addpath ../common;
deltaT = .02;
alphas = [.2 .03 .09 .08 0 0]; % motion model noise parameters
% measurement model noise parameters
sigma_range = .43;
sigma_bearing = .6;
Q_t = [sigma_range^2 0;
0 sigma_bearing^2];
n_robots = 1;
robot_num = 1;
n_landmarks = 15;
[Barcodes, Landmark_Groundtruth, Robots] = loadMRCLAMdataSet(n_robots);
[Robots, timesteps] = sampleMRCLAMdataSet(Robots, deltaT);
% add pose estimate matrix to Robots
Robots{robot_num}.Est = zeros(size(Robots{robot_num}.G,1), 4);
start = 1;
t = Robots{robot_num}.G(start, 1);
% need mean and covariance for the initial pose estimate
poseMean = [Robots{robot_num}.G(start,2);
Robots{robot_num}.G(start,3);
Robots{robot_num}.G(start,4)];
poseCov = 0.01*eye(3);
measurementIndex = 1;
% set up map between barcodes and landmark IDs
codeDict = containers.Map(Barcodes(:,2),Barcodes(:,1));
while (Robots{robot_num}.M(measurementIndex, 1) < t - .05)
measurementIndex = measurementIndex + 1;
end
% loop through all odometry and measurement samples
% updating the robot's pose estimate with each step
% reference table 7.3 in Probabilistic Robotics
for i = start:size(Robots{robot_num}.G, 1)
theta = poseMean(3, 1);
% update time
t = Robots{robot_num}.G(i, 1);
% update movement vector
u_t = [Robots{robot_num}.O(i, 2); Robots{robot_num}.O(i, 3)];
rot = deltaT * u_t(2);
halfRot = rot / 2;
trans = u_t(1) * deltaT;
% calculate the movement Jacobian
G_t = [1 0 trans * -sin(theta + halfRot);
0 1 trans * cos(theta + halfRot);
0 0 1];
% calculate motion covariance in control space
M_t = [(alphas(1) * abs(u_t(1)) + alphas(2) * abs(u_t(2)))^2 0;
0 (alphas(3) * abs(u_t(1)) + alphas(4) * abs(u_t(2)))^2];
% calculate Jacobian to transform motion covariance to state space
V_t = [cos(theta + halfRot) -0.5 * sin(theta + halfRot);
sin(theta + halfRot) 0.5 * cos(theta + halfRot);
0 1];
% calculate pose update from odometry
poseUpdate = [trans * cos(theta + halfRot);
trans * sin(theta + halfRot);
rot];
poseMeanBar = poseMean + poseUpdate;
poseCovBar = G_t * poseCov * G_t' + V_t * M_t * V_t';
% get measurements
[z, measurementIndex] = getObservations(Robots, robot_num, t, measurementIndex, codeDict);
% remove landmark ID from measurement because
% we're trying to live without that
z = z(1:2,:);
% if features are observed
% loop over all features and compute Kalman gain
if z(1,1) > 0.1
for k = 1:size(z, 2) % loop over every observed landmark
% loop over all landmarks and compute MLE correspondence
predZ = zeros(n_landmarks, 1, 2); % predicted measurements
predS = zeros(n_landmarks, 2, 2); % predicted measurement covariances
predH = zeros(n_landmarks, 2, 3); % predicted measurement Jacobians
maxJ = 0;
landmarkIndex = 0;
for j = 1:n_landmarks
xDist = Landmark_Groundtruth(j, 2) - poseMeanBar(1);
yDist = Landmark_Groundtruth(j, 3) - poseMeanBar(2);
q = xDist^2 + yDist^2;
% calculate predicted measurement
predZ(j,:,:) = [sqrt(q);
conBear(atan2(yDist, xDist) - poseMeanBar(3))];
% calculate predicted measurement Jacobian
predH(j,:,:) = [-xDist/sqrt(q) -yDist/sqrt(q) 0;
yDist/q -xDist/q -1];
% calculate predicted measurement covariance
predS(j,:,:) = squeeze(predH(j,:,:)) * poseCovBar ...
* squeeze(predH(j,:,:))' + Q_t;
% calculate probability of measurement correspondence
thisJ = det(2 * pi * squeeze(predS(j,:,:)))^(-0.5) * ...
exp(-0.5 * (z(:,k) - squeeze(predZ(j,:,:)))' ...
* inv(squeeze(predS(j,:,:))) ...
* (z(:,k) - squeeze(predZ(j,:,:))));
% update correspondence if the probability is
% higher than the previous maximum
if thisJ > maxJ
maxJ = thisJ;
landmarkIndex = j;
end
end
% compute Kalman gain
K = poseCovBar * squeeze(predH(landmarkIndex,:,:))' ...
* inv(squeeze(predS(landmarkIndex,:,:)));
% update pose mean and covariance estimates
poseMeanBar = poseMeanBar + K * (z(:,k) - squeeze(predZ(landmarkIndex,:,:)));
poseCovBar = (eye(3) - (K * squeeze(predH(landmarkIndex,:,:)))) * poseCovBar;
end
end
% update pose mean and covariance
poseMean = poseMeanBar;
poseMean(3) = conBear(poseMean(3));
poseCov = poseCovBar;
% add pose mean to estimated position vector
Robots{robot_num}.Est(i,:) = [t poseMean(1) poseMean(2) poseMean(3)];
% calculate error between mean pose and groundtruth
% for testing only
%{
groundtruth = [Robots{robot_num}.G(i, 2);
Robots{robot_num}.G(i, 3);
Robots{robot_num}.G(i, 4)];
error = groundtruth - poseMean;
%}
end
animateMRCLAMdataSet(Robots, Landmark_Groundtruth, timesteps, deltaT);
 and covariance of
and covariance of  . The robot’s expected (or most likely) pose is at
. The robot’s expected (or most likely) pose is at  . Then it corrects for noise in the motion update using the robot’s sensor readings
. Then it corrects for noise in the motion update using the robot’s sensor readings  in order to estimate the state at time
in order to estimate the state at time  to time
to time  . This means it requires less memory and processor time to compute!
. This means it requires less memory and processor time to compute!
 is the robot’s previous x position in meters
is the robot’s previous x position in meters is the robot’s previous y position in meters
is the robot’s previous y position in meters is the robot’s previous heading in radians
is the robot’s previous heading in radians

 is the robot’s linear velocity in meters/sec
is the robot’s linear velocity in meters/sec is the robot’s angular velocity in radians/sec
is the robot’s angular velocity in radians/sec where
where  is the number of measurements at time
is the number of measurements at time  where
where
 is the correspondence between the measurement and landmarks
is the correspondence between the measurement and landmarks
 where
where  is the number of landmarks
is the number of landmarks
 where
where
 is the x position of landmark
is the x position of landmark  is the y position of landmark
is the y position of landmark  is the ID of landmark
is the ID of landmark  , which is the likelihood of the measurements
, which is the likelihood of the measurements 



 , which calculates a new pose based on the previous pose
, which calculates a new pose based on the previous pose 
 is small.
is small. . In order to do this we need to multiply the covariance from the last timestep,
. In order to do this we need to multiply the covariance from the last timestep, 
 . We also need to calculate the additional noise (or uncertainty) associated with the motion that occurred between
. We also need to calculate the additional noise (or uncertainty) associated with the motion that occurred between 
 through
through  are noise parameters that, unfortunately, need to be hand-tuned for the particular robot being used. Also,
are noise parameters that, unfortunately, need to be hand-tuned for the particular robot being used. Also,  is in control space and we need to map it into state space. To do this we need the Jacobian of the motion model with respect to the motion parameters
is in control space and we need to map it into state space. To do this we need the Jacobian of the motion model with respect to the motion parameters 
 . To get the complete updated covariance
. To get the complete updated covariance 
 and it is calculated using the measurement model
and it is calculated using the measurement model  .
.

 ,
,  , and
, and  are the x position, y position, and ID of landmark
are the x position, y position, and ID of landmark 
 is a constant for all measurements. It is a
is a constant for all measurements. It is a  diagonal matrix with noise parameters
diagonal matrix with noise parameters  ,
,  , and
, and  . The sigmas represent the noise for landmark range, bearing, and noise, respectively. Like the alphas in equation (3), the sigmas must be hand-tuned in order to obtain good performance.
. The sigmas represent the noise for landmark range, bearing, and noise, respectively. Like the alphas in equation (3), the sigmas must be hand-tuned in order to obtain good performance.
 is then used to calculate the Kalman gain,
is then used to calculate the Kalman gain,  . The Kalman gain determines how heavily the sensor information should be weighted when correcting the estimated new pose
. The Kalman gain determines how heavily the sensor information should be weighted when correcting the estimated new pose 


 (calculated in equation (7) and the actual measurement
(calculated in equation (7) and the actual measurement  and
and  . The measurement probability is also calculated here but we are not making use of this value.
. The measurement probability is also calculated here but we are not making use of this value.




{kind=link}