
This post is the second in a series of tutorials on SLAM using scanning 2D LIDAR and wheel odometry. The other posts in the series can be found in the links below. The links will be updated as work on the series progresses.
- Intro To LIDAR SLAM and the IRC Dataset
- Matching Scans To A Persistent Map
- SLAM Using LIDAR And Wheel Odometry
- Globally Consistent SLAM With LIDAR
In the previous post I introduced the Intel Research Center (IRC) Dataset and we used it in some basic visualizations. In particular, I used the robot’s odometry to get a rough estimate of its pose over time by simply concatenating the relative transformations between timesteps, 
 :
:

I then used the transform  to project the laser scan at each timestep into the global coordinate frame:
to project the laser scan at each timestep into the global coordinate frame:  where
where  is the set of homogeneous scan points in the global frame,
is the set of homogeneous scan points in the global frame,  is the set of homogeneous points in the robot’s local frame, and is the estimated transform between the global and local coordinate frames. This process is visualized in VisualizeMeasurements.py in my github repo:
is the set of homogeneous points in the robot’s local frame, and is the estimated transform between the global and local coordinate frames. This process is visualized in VisualizeMeasurements.py in my github repo:

Watching this visualization even over a short time, it’s obvious that the robot’s odometry is very noisy and collects drift very quickly. With perfect odometry, the objects measured by the LIDAR would stay static as the robot moves past them. This is clearly not the case. Interestingly, the odometry seems to be fairly reliable for translational motion, but it drifts quickly in rotation. This will be significant later.
How Do We Fix The Drift Problem?
It’s clear to us the robot’s wheel odometry isn’t sufficient to estimate its motion. We know this because we can overlay the robot’s LIDAR scans in our minds and get a sense of how the robot’s estimated motion is deviating from its true motion. If we can do this in our minds, could we tell the robot how to do it? Can the robot use its LIDAR scans to estimate its own motion?
Hopefully you’ve guessed the answer is yes, through a process called scan matching. Basically the goal is to take a new scan from the robot’s LIDAR and find the transformation that best aligns the new scan with either previous scans or some sort of abstracted map. There are many ways to implement this idea and for this tutorial I’m going to demonstrate the simplest method: using the Iterative Closest Point (ICP) algorithm to align the newest LIDAR scan with the previous scan.
Iterative Closest Point In Pictures
The ICP algorithm involves 3 steps: association, transformation, and error evaluation. These are repeated until the scans are aligned satisfactorily. I’ll first demonstrate the process pictorially with an example from the IRL dataset and delve into the math below. Let’s first imagine we want to find the transformation that aligns the two scans pictured below. The previous scan, referred to as the target, is in cyan while the new scan, also called the source is in magenta. The goal is to find the rigid transformation (rotation and translation) that best aligns the source to the target.

Our first step in estimating this transformation is to decide which points in the source scan correspond to the same physical features as points in the target scan. The simplest way to do this is through a nearest neighbor search: points in the source scan are associated to the nearest point in the target scan. In the image below I’ve found the nearest neighbors of each point in the target scan. Associated points are connected with blue lines:

We can immediately see some mistakes in the nearest neighbor search, but in general the associations pictured will pull the source points in the right direction. The next step in the process is transformation. We find the transformation that, when applied to the source points, minimizes the mean-squared distance between the associated points:  where
where  is the final estimated transform and
is the final estimated transform and  and
and  are target points and source points, respectively. The result of this estimation is pictured below:
are target points and source points, respectively. The result of this estimation is pictured below:

After this we evaluate the error in the alignment as  and decide if we need to repeat the above process. In this case our scans still aren’t aligned very well, so we redo the associations with the transformed source points and repeat the process.
and decide if we need to repeat the above process. In this case our scans still aren’t aligned very well, so we redo the associations with the transformed source points and repeat the process.

After five iterations our scans the algorithm finds a pretty good alignment:

The Math Details
ICP is actually pretty straightforward, mathematically. The association step is pretty simple. It can just be a brute-force search for the nearest pairs of points between the source and target scans. If you’re working with large scans though, it’s a good idea to use KD Trees for this step.
The real trick to ICP is in the transformation step. Basically, we find the covariance between the two point sets, the matrix  .
.

Where  is a matrix whose
is a matrix whose  column is
column is  or the source point expressed relative to the centroid of the source point set
or the source point expressed relative to the centroid of the source point set  . Similarly,
. Similarly,  is a matrix whose column is
is a matrix whose column is  . Once we have the covariance matrix , we find the rotation
. Once we have the covariance matrix , we find the rotation  between the two point clouds using singular value decomposition:
between the two point clouds using singular value decomposition:

If you’re wondering how you break the matrix down into  ,
,  , and
, and  , know that most linear algebra packages (including matlab and numpy) have functions for SVD. That’s about as far as you need to get into it. If you’re interested though, the wikipedia page has some good details.
, know that most linear algebra packages (including matlab and numpy) have functions for SVD. That’s about as far as you need to get into it. If you’re interested though, the wikipedia page has some good details.
We’ve found the rotation between the point sets, now we just need the translation  . Luckily it’s pretty simple, just the difference between the centroids of the point clouds
. Luckily it’s pretty simple, just the difference between the centroids of the point clouds  .
.
Once we have our translation and rotation we evaluate the alignment error as  . We use this to determine if we should quit or iterate again. Normally we stop the process if the error at the current step is below a threshold, if the difference between the error at the current step and the previous step’s error is below a threshold, or if we’ve reached a maximum number of iterations.
. We use this to determine if we should quit or iterate again. Normally we stop the process if the error at the current step is below a threshold, if the difference between the error at the current step and the previous step’s error is below a threshold, or if we’ve reached a maximum number of iterations.
Below is a visualization of a simple ICP motion estimation algorithm. It simply aligns the newest scan to the previous scan to find the motion of the robot between scans:

Note that this method for motion estimation works pretty well sometimes. If the robot is near large sections of wall at different angles it can estimate its transformation between scans pretty reliably. This is because it has good environmental queues to its motion in all directions. On the other hand, if the robot is in a mostly straight hallway, there’s really nothing in its measurements that will tell it how it’s moving along the hallway. One alignment is as good as any other as long as the walls line up. In these cases the robot’s estimates of its translation are very poor. Similarly, if there just aren’t a lot of unique, persistent features in the scan, which happens sometimes when the robot approaches corners, there aren’t any good cues for the robot to estimate its rotation.
So, matching successive LIDAR scans via the iterative closest point algorithm can give our robot some information about its own movement. However, this on its own is not enough to provide a reliable motion estimate. Luckily, our robot has wheel odometry in addition to LIDAR. Even luckier, in fact, ICP is pretty reliable at estimating rotations but poor with translation in some cases. The wheel odometry, on the other hand, gives us very accurate translation but it is very unreliable with rotation. Next time, we’ll experiment with fusing information from these two sensors to create a more reliable motion estimate.
The Code
Below you can see an implementation of the ICP algorithm in python. You can find the full class, Align2D.py, in my github repo as well as a demonstration of its use in VisualizeICP.py.
# uses the iterative closest point algorithm to find the # transformation between the source and target point clouds # that minimizes the sum of squared errors between nearest # neighbors in the two point clouds # params: # max_iter: int, max number of iterations # min_delta_err: float, minimum change in alignment error def AlignICP(self, max_iter, min_delta_err): mean_sq_error = 1.0e6 # initialize error as large number delta_err = 1.0e6 # change in error (used in stopping condition) T = self.init_T num_iter = 0 # number of iterations tf_source = self.source while delta_err > min_delta_err and num_iter < max_iter: # find correspondences via nearest-neighbor search matched_trg_pts,matched_src_pts,indices = self.FindCorrespondences(tf_source) # find alingment between source and corresponding target points via SVD # note: svd step doesn't use homogeneous points new_T = self.AlignSVD(matched_src_pts, matched_trg_pts) # update transformation between point sets T = np.dot(T,new_T) # apply transformation to the source points tf_source = np.dot(self.source,T.T) # find mean squared error between transformed source points and target points new_err = 0 for i in range(len(indices)): if indices[i] != -1: diff = tf_source[i,:2] - self.target[indices[i],:2] new_err += np.dot(diff,diff.T) new_err /= float(len(matched_trg_pts)) # update error and calculate delta error delta_err = abs(mean_sq_error - new_err) mean_sq_error = new_err num_iter += 1 return T # uses singular value decomposition to find the # transformation from the target to the source point cloud # assumes source and target point clounds are ordered such that # corresponding points are at the same indices in each array # # params: # source: numpy array representing source pointcloud # target: numpy array representing target pointcloud # returns: # T: transformation between the two point clouds def AlignSVD(self, source, target): # first find the centroids of both point clouds src_centroid = self.GetCentroid(source) trg_centroid = self.GetCentroid(target) # get the point clouds in reference to their centroids source_centered = source - src_centroid target_centered = target - trg_centroid # get cross covariance matrix M M = np.dot(source_centered.T,target_centered) # get singular value decomposition of the cross covariance matrix U,W,V_t = np.linalg.svd(M) # get rotation between the two point clouds R = np.dot(V_t.T,U.T) # get the translation (simply the difference between the point clound centroids) t = trg_centroid - src_centroid # assemble translation and rotation into a transformation matrix T = np.identity(3) T[:2,2] = np.squeeze(t) T[:2,:2] = R return T def GetCentroid(self, points): point_sum = np.sum(points,axis=0) return point_sum / float(len(points))







 and covariance matrix
and covariance matrix  need to contain entries for the robot’s pose as well as the landmark locations. The big difference here is that we don’t know how many landmarks we’ll be tracking. This means we need to add new landmarks to the state as we find them.
need to contain entries for the robot’s pose as well as the landmark locations. The big difference here is that we don’t know how many landmarks we’ll be tracking. This means we need to add new landmarks to the state as we find them. , between each landmark and the measurement, and we instead search for the landmark association with the minimum Mahalanobis distance. This is just another way of doing maximum likelihood association. Note also we’re using the same
, between each landmark and the measurement, and we instead search for the landmark association with the minimum Mahalanobis distance. This is just another way of doing maximum likelihood association. Note also we’re using the same  matrix as in the
matrix as in the ![\begin{align*} \text{for all}&\text{ measurements } z_t^i=[r_t^i\ \phi_t^i]^T \text{ do} \\ &\begin{bmatrix} \bar{\mu}_{N_t+1,x} \\ \bar{\mu}_{N_t+1,y} \end{bmatrix} = \begin{bmatrix} \bar{\mu}_{t,x} \\ \bar{\mu}_{t,y} \end{bmatrix} + r_t^i \begin{bmatrix} \cos(\phi_t^i+\bar{\mu}_{t,\theta}) \\ \sin(\phi_t^i+\bar{\mu}_{t,\theta}) \end{bmatrix} \\ \text{for}&\text{ all landmarks } k \text{ to } N_{t+1} \text{ do} \\ &q = (m_{k,x} - \bar{\mu}_{t,x})^2 + (m_{k,y} - \bar{\mu}_{t,y})^2 \\ &r = \sqrt{q} \\ &\hat{z}_t^k = \begin{bmatrix} \sqrt{q} \\ \text{atan2}(m_{k,y}-\bar{\mu}_{t,y},\ m_{k,x}-\bar{\mu}_{t,x})-\bar{\mu}_{t,\theta} \end{bmatrix} \\ &F_{x,k} = \begin{bmatrix} 1&0&0&0&\dots&0&0&\dots&0\\0&1&0&0&\dots&0&0&\dots&0\\0&0&1&0&\dots&0&0&\dots&0\\0&0&0&0&\dots&1&0&\dots&0\\0&0&0&0&\dots&0&1&\dots&0 \end{bmatrix} \\ &h_t^k = \begin{bmatrix} -\delta_{k,x}/r & -\delta_{k,y}/r & 0 & \delta_{k,x}/r & \delta_{k,y}/r \\ \delta_{k,y}/q & -\delta_{k,x}/q & -1 & -\delta_{k,y}/q & \delta_{k,x}/q \end{bmatrix} \\ &H_t^k=h_t^kF_{x,k}\\ &\Psi_k=H_t^k\bar{\Sigma}_t[H_t^k]^T + Q_t \\ &\pi_k=(z_t^i-\hat{z}_t^k)^T\Psi_k^{-1}(z_t^i-\hat{z}_t^k) \\ \text{end}&\text{for} \\ \pi_{N_t+1}&=\alpha \\ j(i) &= \text{argmin}_k\ \pi_k\\ N_t &= \text{max}\{N_t,j(i)\} \\ \text{endfor}& \end{align*}](https://i0.wp.com/andrewjkramer.net/wp-content/ql-cache/quicklatex.com-71b884a246c54720097fd6983f7a37dc_l3.png?resize=414%2C591&ssl=1 "Rendered by QuickLaTeX.com")
 . We finally associate the measurement to the landmark with the lowest distance. If no landmark has a distance lower than
. We finally associate the measurement to the landmark with the lowest distance. If no landmark has a distance lower than  . Now when doing SLAM the state vector has dimension
. Now when doing SLAM the state vector has dimension  where
where  is the number of landmarks in our problem. In this formulation the coordinates of landmark
is the number of landmarks in our problem. In this formulation the coordinates of landmark  (
( and
and  ) are found at indices
) are found at indices  and
and  of the state vector.
of the state vector. to
to  where
where  .
.  matrix where the rightmost block is a
matrix where the rightmost block is a 

 is the motion update calculated from the control input at timestep
is the motion update calculated from the control input at timestep  (not the raw control input),
(not the raw control input),  is the motion Jacobian evaluated at timestep
is the motion Jacobian evaluated at timestep  is a
is a  matrix. This time it will be
matrix. This time it will be  , with the subscript
, with the subscript  signifying that it relates the pose
signifying that it relates the pose  to landmark
to landmark  matrix. The
matrix. The  identity block occupying the lower two rows and starting at the index
identity block occupying the lower two rows and starting at the index  where
where 

 is the measurement Jacobian. With only these augmentations we can change the localization algorithm with known correspondence to a SLAM algorithm with known correspondence. Not too complicated, right?
is the measurement Jacobian. With only these augmentations we can change the localization algorithm with known correspondence to a SLAM algorithm with known correspondence. Not too complicated, right?![z_t^i = [r_t^i\ \phi_t^i\ s_t^i]^T](https://i0.wp.com/andrewjkramer.net/wp-content/ql-cache/quicklatex.com-2748ddc649f7f00566bd0e4f698c3cd3_l3.png?resize=114%2C20&ssl=1 "Rendered by QuickLaTeX.com") where
where  is the measurement to landmark
is the measurement to landmark  at time
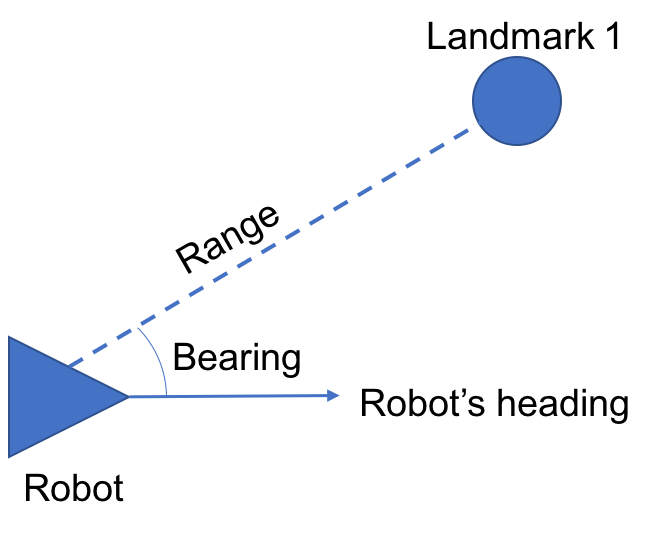
at time  , bearing
, bearing  , and, crucially, identity of the landmark being measured
, and, crucially, identity of the landmark being measured  . This could be interpreted as “landmark
. This could be interpreted as “landmark  is
is  meters away, at a bearing of
meters away, at a bearing of  radians.”
radians.”![z_t^i=[r_t^i\ \phi_t^i]^T](https://i0.wp.com/andrewjkramer.net/wp-content/ql-cache/quicklatex.com-5c2c2413b6a0bc6a72e04a501e2ac888_l3.png?resize=94%2C20&ssl=1 "Rendered by QuickLaTeX.com") . So we are no longer directly telling the robot to which landmark each measurement corresponds. Without knowledge of this correspondence measurements are basically useless to our robot. Sure, it knows the location of a landmark relative to its own location. But without knowing where that landmark is in the world it can’t use that information to refine its estimate of its pose.
. So we are no longer directly telling the robot to which landmark each measurement corresponds. Without knowledge of this correspondence measurements are basically useless to our robot. Sure, it knows the location of a landmark relative to its own location. But without knowing where that landmark is in the world it can’t use that information to refine its estimate of its pose.
 , map
, map  , past measurements
, past measurements  , and past control inputs
, and past control inputs  , which landmark has the highest probability of producing measurement
, which landmark has the highest probability of producing measurement  ?
?![\begin{align*} \text{for all}&\text{ measurements } z_t^i=[r_t^i\ \phi_t^i]^T \text{ do} \\ \text{for}&\text{ all landmarks } k \text{ in the map } m \text{ do} \\ &q = (m_{k,x} - \bar{\mu}_{t,x})^2 + (m_{k,y} - \bar{\mu}_{t,y})^2 \\ &\hat{z}_t^k = \begin{bmatrix} \sqrt{q} \\ \text{atan2}(m_{k,y}-\bar{\mu}_{t,y},\ m_{k,x}-\bar{\mu}_{t,x})-\bar{\mu}_{t,\theta} \end{bmatrix} \\ &H_t^k = \begin{bmatrix} -\frac{m_{k,x}-\bar{\mu}_{t,x}}{\sqrt{q}} & -\frac{m_{k,y}-\bar{\mu}_{t,y}}{\sqrt{q}} & 0 \\ \frac{m_{k,y}-\bar{\mu}_{t,y}}{q} & -\frac{m_{k,x}-\bar{\mu}_{t,x}}{q} & -1\end{bmatrix} \\ &S_t^k = H_t^k \bar{\Sigma}_t [H_t^k]^T + Q_t \\ \text{end}&\text{for} \\ j(i) &= \text{argmax}_k\ \text{det}(2\pi S_t^k)^{-\frac{1}{2}} \text{exp}\{-\frac{1}{2}(z_t^i-\hat{z}_t^k)[S_t^k]^{-1}(z_t^i-\hat{z}_t^k)^T\}\\ \text{endfor}& \end{align*}](https://i0.wp.com/andrewjkramer.net/wp-content/ql-cache/quicklatex.com-64e1846930d8c3fb71680afa0184f6e8_l3.png?resize=509%2C311&ssl=1 "Rendered by QuickLaTeX.com")
 is the estimated correspondence
is the estimated correspondence  and covariance of
and covariance of  . The robot’s expected (or most likely) pose is at
. The robot’s expected (or most likely) pose is at  . Then it corrects for noise in the motion update using the robot’s sensor readings
. Then it corrects for noise in the motion update using the robot’s sensor readings  in order to estimate the state at time
in order to estimate the state at time  to time
to time  . This means it requires less memory and processor time to compute!
. This means it requires less memory and processor time to compute!
 is the robot’s previous x position in meters
is the robot’s previous x position in meters is the robot’s previous y position in meters
is the robot’s previous y position in meters is the robot’s previous heading in radians
is the robot’s previous heading in radians

 is the robot’s linear velocity in meters/sec
is the robot’s linear velocity in meters/sec is the robot’s angular velocity in radians/sec
is the robot’s angular velocity in radians/sec where
where  where
where
 is the correspondence between the measurement and landmarks
is the correspondence between the measurement and landmarks
 where
where  where
where
 is the x position of landmark
is the x position of landmark  is the y position of landmark
is the y position of landmark  is the ID of landmark
is the ID of landmark  , which is the likelihood of the measurements
, which is the likelihood of the measurements 



 , which calculates a new pose based on the previous pose
, which calculates a new pose based on the previous pose 
 is small.
is small. . In order to do this we need to multiply the covariance from the last timestep,
. In order to do this we need to multiply the covariance from the last timestep, 
 . We also need to calculate the additional noise (or uncertainty) associated with the motion that occurred between
. We also need to calculate the additional noise (or uncertainty) associated with the motion that occurred between 
 through
through  are noise parameters that, unfortunately, need to be hand-tuned for the particular robot being used. Also,
are noise parameters that, unfortunately, need to be hand-tuned for the particular robot being used. Also,  is in control space and we need to map it into state space. To do this we need the Jacobian of the motion model with respect to the motion parameters
is in control space and we need to map it into state space. To do this we need the Jacobian of the motion model with respect to the motion parameters 
 . To get the complete updated covariance
. To get the complete updated covariance 
 and it is calculated using the measurement model
and it is calculated using the measurement model  .
.

 ,
,  , and
, and  are the x position, y position, and ID of landmark
are the x position, y position, and ID of landmark 
 is a constant for all measurements. It is a
is a constant for all measurements. It is a  diagonal matrix with noise parameters
diagonal matrix with noise parameters  ,
,  , and
, and  . The sigmas represent the noise for landmark range, bearing, and noise, respectively. Like the alphas in equation (3), the sigmas must be hand-tuned in order to obtain good performance.
. The sigmas represent the noise for landmark range, bearing, and noise, respectively. Like the alphas in equation (3), the sigmas must be hand-tuned in order to obtain good performance.
 is then used to calculate the Kalman gain,
is then used to calculate the Kalman gain,  . The Kalman gain determines how heavily the sensor information should be weighted when correcting the estimated new pose
. The Kalman gain determines how heavily the sensor information should be weighted when correcting the estimated new pose 


 (calculated in equation (7) and the actual measurement
(calculated in equation (7) and the actual measurement  and
and  . The measurement probability is also calculated here but we are not making use of this value.
. The measurement probability is also calculated here but we are not making use of this value.





{kind=link}