
This tutorial is part of a series on Simultaneous Localization and Mapping (SLAM) using the extended Kalman filter. See the following for other tutorials in the series:
- Introduction
- Step 0: Introducing the Dataset
- Step 1: Localization With Known Correlation
- Step 2: Localization With Unknown Correlation
- Step 3: SLAM With Known Correlation
This tutorial builds on the previous tutorials on localization and SLAM. When doing SLAM with unknown measurement correspondence we no longer have any prior information about the robot’s environment. When we get a measurement we don’t know to which landmark it corresponds. This means we have to use a maximum likelihood measurement association method similar to the one used in the tutorial on localization with unknown correlation. There’s another, more difficult challenge though. Not only do we have no idea where the landmarks are in the environment, we don’t even know how many landmarks exist in the environment. This is the most difficult scenario for a SLAM system but, as you’ll see it only takes a couple of tweaks to the SLAM algorithm presented in the previous tutorial to handle this situation.
The State And Covariance Matrices
As in the previous tutorial on SLAM with known correlation, the state mean vector  and covariance matrix
and covariance matrix  need to contain entries for the robot’s pose as well as the landmark locations. The big difference here is that we don’t know how many landmarks we’ll be tracking. This means we need to add new landmarks to the state as we find them.
need to contain entries for the robot’s pose as well as the landmark locations. The big difference here is that we don’t know how many landmarks we’ll be tracking. This means we need to add new landmarks to the state as we find them.
You may notice this presents a problem for the complexity of the algorithm. Every time a new landmark is added to the state the state covariance matrix grows, adding complexity to every calculation involving the covariance matrix, of which there are several. This is why the complexity of EKF SLAM scales with the number of landmarks in the state. This isn’t a problem if the robot always stays in the same area and if it can accurately associate measurements to existing landmarks. In this case the number of landmarks is roughly constant so the complexity of the algorithm stays constant. However, if the robot explores new areas the number of landmarks being tracked, and thus the complexity of the algorithm, grows with time. In this case it can become computationally intractable very quickly.
Limiting Complexity
There are a number of ways to limit the growth in EKF SLAM’s complexity. For instance, one can remove landmarks from the state if they haven’t been observed for a certain amount of time. Or, for a more sophisticated approach, one could keep two classes of landmarks: active and inactive. A landmark that hasn’t been observed for a certain amount of time is moved from the state matrix to the inactive set. In this formulation only the active landmarks are used in computing the state estimate, but if an inactive landmark is observed it can be added back to the state. This would prevent the complexity of the algorithm from growing out of control but also allow the robot to recognize previously visited locations, limiting drift in the state estimate. This method requires an extremely reliable measurement association algorithm, however. Without bulletproof measurement associations it is more likely to create new landmarks than associate measurements to landmarks in the inactive set. For this one usually needs more information from a measurement than just range and bearing. For instance, it is helpful to have information about the landmark’s shape or appearance in addition to its location relative to the robot.
Measurement Association
Our measurement association algorithm for SLAM is very similar to the one we used in localization with unknown correspondence. There’s an important additional requirement though. When doing localization we just need to decide which landmark is most likely to be associated with the current measurement. With SLAM we also need to decide if its more likely that a given measurement is associated with an existing landmark or with a new landmark.
As in the case for localization, for each new measurement we’ll loop over every known landmark and calculate the likelihood the measurement associates to that landmark. We then take the landmark most likely to be associated to the current measurement. If its likelihood of association is above a threshold value, we associate the measurement to that landmark. If its likelihood is below the threshold value we instead use that measurement to create a new landmark. In the algorithm below we calculate the Mahalanobis distance,  , between each landmark and the measurement, and we instead search for the landmark association with the minimum Mahalanobis distance. This is just another way of doing maximum likelihood association. Note also we’re using the same
, between each landmark and the measurement, and we instead search for the landmark association with the minimum Mahalanobis distance. This is just another way of doing maximum likelihood association. Note also we’re using the same  matrix as in the previous tutorial.
matrix as in the previous tutorial.
![\begin{align*} \text{for all}&\text{ measurements } z_t^i=[r_t^i\ \phi_t^i]^T \text{ do} \\ &\begin{bmatrix} \bar{\mu}_{N_t+1,x} \\ \bar{\mu}_{N_t+1,y} \end{bmatrix} = \begin{bmatrix} \bar{\mu}_{t,x} \\ \bar{\mu}_{t,y} \end{bmatrix} + r_t^i \begin{bmatrix} \cos(\phi_t^i+\bar{\mu}_{t,\theta}) \\ \sin(\phi_t^i+\bar{\mu}_{t,\theta}) \end{bmatrix} \\ \text{for}&\text{ all landmarks } k \text{ to } N_{t+1} \text{ do} \\ &q = (m_{k,x} - \bar{\mu}_{t,x})^2 + (m_{k,y} - \bar{\mu}_{t,y})^2 \\ &r = \sqrt{q} \\ &\hat{z}_t^k = \begin{bmatrix} \sqrt{q} \\ \text{atan2}(m_{k,y}-\bar{\mu}_{t,y},\ m_{k,x}-\bar{\mu}_{t,x})-\bar{\mu}_{t,\theta} \end{bmatrix} \\ &F_{x,k} = \begin{bmatrix} 1&0&0&0&\dots&0&0&\dots&0\\0&1&0&0&\dots&0&0&\dots&0\\0&0&1&0&\dots&0&0&\dots&0\\0&0&0&0&\dots&1&0&\dots&0\\0&0&0&0&\dots&0&1&\dots&0 \end{bmatrix} \\ &h_t^k = \begin{bmatrix} -\delta_{k,x}/r & -\delta_{k,y}/r & 0 & \delta_{k,x}/r & \delta_{k,y}/r \\ \delta_{k,y}/q & -\delta_{k,x}/q & -1 & -\delta_{k,y}/q & \delta_{k,x}/q \end{bmatrix} \\ &H_t^k=h_t^kF_{x,k}\\ &\Psi_k=H_t^k\bar{\Sigma}_t[H_t^k]^T + Q_t \\ &\pi_k=(z_t^i-\hat{z}_t^k)^T\Psi_k^{-1}(z_t^i-\hat{z}_t^k) \\ \text{end}&\text{for} \\ \pi_{N_t+1}&=\alpha \\ j(i) &= \text{argmin}_k\ \pi_k\\ N_t &= \text{max}\{N_t,j(i)\} \\ \text{endfor}& \end{align*}](https://i0.wp.com/andrewjkramer.net/wp-content/ql-cache/quicklatex.com-71b884a246c54720097fd6983f7a37dc_l3.png?resize=414%2C591 "Rendered by QuickLaTeX.com")
To summarize, at the start of the algorithm we create a new landmark at the end of the state mean vector . We then calculate the Mahalanobis distance between all landmarks and the current measurement. We then set the distance for the newly created landmark to a threshold value,  . We finally associate the measurement to the landmark with the lowest distance. If no landmark has a distance lower than , the new landmark is added to the state.
. We finally associate the measurement to the landmark with the lowest distance. If no landmark has a distance lower than , the new landmark is added to the state.
The Complete Algorithm
The code for the complete algorithm is shown below. Note the algorithm is very sensitive to incorrect measurement association. That’s why, when we’re doing measurement association, we keep track of the two best associations (line 113). Then we check to make sure the best association is significantly better than the second best (line 154). If not, we consider the measurement to be ambiguous and discard it. Even with this precaution the algorithm still occasionally makes bad associations. Because of this the performance of the algorithm is way less than perfect. There are several ways to deal with this, such as multi-hypothesis tracking. I may go into detail on this method in a later post.
addpath ../common;
deltaT = .02;
alphas = [.11 .01 .18 .08 0 0]; % motion model noise parameters
% measurement model noise parameters
Q_t = [11.7 0;
0 0.18];
n_robots = 1;
robot_num = 1;
[Barcodes, Landmark_Groundtruth, Robots] = loadMRCLAMdataSet(n_robots);
[Robots, timesteps] = sampleMRCLAMdataSet(Robots, deltaT);
% add pose estimate matrix to Robots
Robots{robot_num}.Est = zeros(size(Robots{robot_num}.G,1), 4);
start = 600;
t = Robots{robot_num}.G(start, 1);
% initialize state mean
stateMean = [Robots{robot_num}.G(start,2);
Robots{robot_num}.G(start,3);
Robots{robot_num}.G(start,4)];
stateCov = zeros(3, 3);
stateCov(1:3,1:3) = 0.001;
measurementIndex = 1;
meas_count = 0;
n_landmarks = 0;
% set up map between barcodes and landmark IDs
codeDict = containers.Map(Barcodes(:,2),Barcodes(:,1));
% loop through all odometry and measurement samples
% updating the robot's pose estimate with each step
% reference table 10.1 in Probabilistic Robotics
for i = start:size(Robots{robot_num}.G, 1)
% update time
t = Robots{robot_num}.G(i, 1);
% update movement vector
u_t = [Robots{robot_num}.O(i, 2); Robots{robot_num}.O(i, 3)];
% update robot bearing
theta = stateMean(3, 1);
rot = deltaT * u_t(2);
halfRot = rot / 2;
trans = u_t(1) * deltaT;
% calculate pose update from odometry
poseUpdate = [trans * cos(theta + halfRot);
trans * sin(theta + halfRot);
rot];
% calculate updated state mean
F_x = [eye(3) zeros(3, size(stateMean, 1) - 3)];
stateMeanBar = stateMean + F_x' * poseUpdate;
stateMeanBar(3) = conBear(stateMeanBar(3));
% calculate movement jacobian
g_t = [0 0 trans * -sin(theta + halfRot);
0 0 trans * cos(theta + halfRot);
0 0 0];
G_t = eye(size(stateMean, 1)) + F_x' * g_t * F_x;
% calculate motion covariance in control space
M_t = [(alphas(1) * abs(u_t(1)) + alphas(2) * abs(u_t(2)))^2 0;
0 (alphas(3) * abs(u_t(1)) + alphas(4) * abs(u_t(2)))^2];
% calculate Jacobian to transform motion covariance to state space
V_t = [cos(theta + halfRot) -0.5 * sin(theta + halfRot);
sin(theta + halfRot) 0.5 * cos(theta + halfRot);
0 1];
% update state covariance
R_t = V_t * M_t * V_t';
stateCovBar = (G_t * stateCov * G_t') + (F_x' * R_t * F_x);
% get measurements
[z, measurementIndex] = getObservations(Robots, robot_num, t, measurementIndex, codeDict);
% if features are observed
% loop over all features and compute Kalman gain
if z(3,1) > 0
for k = 1:size(z, 2) % loop over every measurement
predZ = zeros(2, n_landmarks+1);
predPsi = zeros(n_landmarks+1, 2, 2);
predH = zeros(n_landmarks+1, 2, 2*(n_landmarks+1)+3);
pi_k = zeros(n_landmarks+1, 1);
% create temporary new landmark at observed position
temp_mark = [stateMeanBar(1) + z(1,k) * cos(z(2,k) + stateMeanBar(3));
stateMeanBar(2) + z(1,k) * sin(z(2,k) + stateMeanBar(3))];
stateMeanTemp = [stateMeanBar;
temp_mark];
stateCovTemp = [stateCovBar zeros(size(stateCovBar,1),2);
zeros(2,size(stateCovBar,2) + 2)];
% initialize covariance for new landmark proportional
% to range measurement squared
for ii = (size(stateCovTemp,1)-1):(size(stateCovTemp,1))
stateCovTemp(ii,ii) = (z(1,k)^2)/130;
end
% loop over all landmarks (including the temp landmark) and
% compute likelihood of correspondence with the new landmark
max_j = 0;
min_pi = 10*ones(2,1);
for j = 1:n_landmarks+1
delta = [stateMeanTemp(2*j+2) - stateMeanTemp(1);
stateMeanTemp(2*j+3) - stateMeanTemp(2)];
q = delta' * delta;
r = sqrt(q);
predZ(:,j) = [r;
conBear(atan2(delta(2), delta(1)) - stateMeanTemp(3))];
F_xj = [eye(3) zeros(3,2*j-2) zeros(3,2) zeros(3,2*(n_landmarks+1) - 2*j);
zeros(2,3) zeros(2,2*j-2) eye(2) zeros(2,2*(n_landmarks+1) - 2*j)];
h_t = [-delta(1)/r -delta(2)/r 0 delta(1)/r delta(2)/r;
delta(2)/q -delta(1)/q -1 -delta(2)/q delta(1)/q];
predH(j,:,:) = h_t * F_xj;
predPsi(j,:,:) = squeeze(predH(j,:,:)) * stateCovTemp * ...
squeeze(predH(j,:,:))' + Q_t;
if j <= n_landmarks
pi_k(j) = ((z(1:2,k)-predZ(:,j))'...
/(squeeze(predPsi(j,:,:))))...
*(z(1:2,k)-predZ(:,j));
else
pi_k(j) = 0.84; % alpha: min mahalanobis distance to
% add landmark to map
end
% track best two associations
if pi_k(j) < min_pi(1)
min_pi(2) = min_pi(1);
max_j = j;
min_pi(1) = pi_k(j);
end
end
H = squeeze(predH(max_j,:,:));
% best association must be significantly better than
% the second best, otherwise the measurement is
% thrown out
if (min_pi(2) / min_pi(1) > 1.6)
meas_count = meas_count + 1;
% if a landmark is added to the map expand the
% state and covariance matrices
if max_j > n_landmarks
stateMeanBar = stateMeanTemp;
stateCovBar = stateCovTemp;
n_landmarks = n_landmarks + 1;
% if measurement is associated to an existing landmark
% truncate h matrix to prevent dim mismatch
else
H = H(:,1:n_landmarks*2 + 3);
K = stateCovBar * H' / (squeeze(predPsi(max_j,:,:)));
stateMeanBar = stateMeanBar + K * ...
(z(1:2,k) - predZ(:,max_j));
stateMeanBar(3) = conBear(stateMeanBar(3));
stateCovBar = (eye(size(stateCovBar)) - (K * H)) * stateCovBar;
end
end
end
end
% update state mean and covariance
stateMean = stateMeanBar;
stateCov = stateCovBar;
% add new pose mean to estimated poses
Robots{robot_num}.Est(i,:) = [t stateMean(1) stateMean(2) stateMean(3)];
end
p_loss = path_loss(Robots, robot_num, start);
disp(p_loss);
Robots{robot_num}.Map = stateMean;
%animateMRCLAMdataSet(Robots, Landmark_Groundtruth, timesteps, deltaT);
 . Now when doing SLAM the state vector has dimension
. Now when doing SLAM the state vector has dimension  where
where  is the number of landmarks in our problem. In this formulation the coordinates of landmark
is the number of landmarks in our problem. In this formulation the coordinates of landmark  (
( and
and  ) are found at indices
) are found at indices  and
and  of the state vector.
of the state vector. to
to  where
where  .
.  matrix where the rightmost block is a
matrix where the rightmost block is a 

 is the motion update calculated from the control input at timestep
is the motion update calculated from the control input at timestep  (not the raw control input),
(not the raw control input),  is the motion Jacobian evaluated at timestep
is the motion Jacobian evaluated at timestep  is a
is a  is the constant process noise covariance.
is the constant process noise covariance. matrix. This time it will be
matrix. This time it will be  , with the subscript
, with the subscript  signifying that it relates the pose
signifying that it relates the pose  to landmark
to landmark  matrix. The
matrix. The  identity block occupying the lower two rows and starting at the index
identity block occupying the lower two rows and starting at the index  where
where 

 is the measurement Jacobian. With only these augmentations we can change the localization algorithm with known correspondence to a SLAM algorithm with known correspondence. Not too complicated, right?
is the measurement Jacobian. With only these augmentations we can change the localization algorithm with known correspondence to a SLAM algorithm with known correspondence. Not too complicated, right?![z_t^i = [r_t^i\ \phi_t^i\ s_t^i]^T](https://i0.wp.com/andrewjkramer.net/wp-content/ql-cache/quicklatex.com-2748ddc649f7f00566bd0e4f698c3cd3_l3.png?resize=114%2C20 "Rendered by QuickLaTeX.com") where
where  is the measurement to landmark
is the measurement to landmark  at time
at time  . This vector contains the range
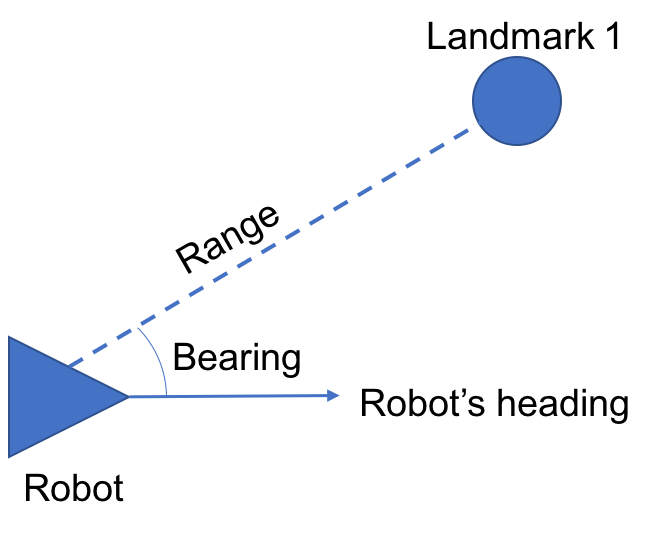
. This vector contains the range  , bearing
, bearing  , and, crucially, identity of the landmark being measured
, and, crucially, identity of the landmark being measured  . This could be interpreted as “landmark
. This could be interpreted as “landmark  is
is  meters away, at a bearing of
meters away, at a bearing of  radians.”
radians.”![z_t^i=[r_t^i\ \phi_t^i]^T](https://i0.wp.com/andrewjkramer.net/wp-content/ql-cache/quicklatex.com-5c2c2413b6a0bc6a72e04a501e2ac888_l3.png?resize=94%2C20 "Rendered by QuickLaTeX.com") . So we are no longer directly telling the robot to which landmark each measurement corresponds. Without knowledge of this correspondence measurements are basically useless to our robot. Sure, it knows the location of a landmark relative to its own location. But without knowing where that landmark is in the world it can’t use that information to refine its estimate of its pose.
. So we are no longer directly telling the robot to which landmark each measurement corresponds. Without knowledge of this correspondence measurements are basically useless to our robot. Sure, it knows the location of a landmark relative to its own location. But without knowing where that landmark is in the world it can’t use that information to refine its estimate of its pose.
 , map
, map  , past measurements
, past measurements  , and past control inputs
, and past control inputs  , which landmark has the highest probability of producing measurement
, which landmark has the highest probability of producing measurement  ?
?![\begin{align*} \text{for all}&\text{ measurements } z_t^i=[r_t^i\ \phi_t^i]^T \text{ do} \\ \text{for}&\text{ all landmarks } k \text{ in the map } m \text{ do} \\ &q = (m_{k,x} - \bar{\mu}_{t,x})^2 + (m_{k,y} - \bar{\mu}_{t,y})^2 \\ &\hat{z}_t^k = \begin{bmatrix} \sqrt{q} \\ \text{atan2}(m_{k,y}-\bar{\mu}_{t,y},\ m_{k,x}-\bar{\mu}_{t,x})-\bar{\mu}_{t,\theta} \end{bmatrix} \\ &H_t^k = \begin{bmatrix} -\frac{m_{k,x}-\bar{\mu}_{t,x}}{\sqrt{q}} & -\frac{m_{k,y}-\bar{\mu}_{t,y}}{\sqrt{q}} & 0 \\ \frac{m_{k,y}-\bar{\mu}_{t,y}}{q} & -\frac{m_{k,x}-\bar{\mu}_{t,x}}{q} & -1\end{bmatrix} \\ &S_t^k = H_t^k \bar{\Sigma}_t [H_t^k]^T + Q_t \\ \text{end}&\text{for} \\ j(i) &= \text{argmax}_k\ \text{det}(2\pi S_t^k)^{-\frac{1}{2}} \text{exp}\{-\frac{1}{2}(z_t^i-\hat{z}_t^k)[S_t^k]^{-1}(z_t^i-\hat{z}_t^k)^T\}\\ \text{endfor}& \end{align*}](https://i0.wp.com/andrewjkramer.net/wp-content/ql-cache/quicklatex.com-64e1846930d8c3fb71680afa0184f6e8_l3.png?resize=509%2C311 "Rendered by QuickLaTeX.com")
 is the estimated correspondence
is the estimated correspondence  and covariance of
and covariance of  . The robot’s expected (or most likely) pose is at
. The robot’s expected (or most likely) pose is at  . Then it corrects for noise in the motion update using the robot’s sensor readings
. Then it corrects for noise in the motion update using the robot’s sensor readings  in order to estimate the state at time
in order to estimate the state at time  to time
to time  . This means it requires less memory and processor time to compute!
. This means it requires less memory and processor time to compute!
 is the robot’s previous x position in meters
is the robot’s previous x position in meters is the robot’s previous y position in meters
is the robot’s previous y position in meters is the robot’s previous heading in radians
is the robot’s previous heading in radians

 is the robot’s linear velocity in meters/sec
is the robot’s linear velocity in meters/sec is the robot’s angular velocity in radians/sec
is the robot’s angular velocity in radians/sec where
where  where
where
 is the correspondence between the measurement and landmarks
is the correspondence between the measurement and landmarks
 where
where  where
where
 is the x position of landmark
is the x position of landmark  is the y position of landmark
is the y position of landmark  is the ID of landmark
is the ID of landmark  , which is the likelihood of the measurements
, which is the likelihood of the measurements 



 , which calculates a new pose based on the previous pose
, which calculates a new pose based on the previous pose 
 is small.
is small. . In order to do this we need to multiply the covariance from the last timestep,
. In order to do this we need to multiply the covariance from the last timestep, 
 . We also need to calculate the additional noise (or uncertainty) associated with the motion that occurred between
. We also need to calculate the additional noise (or uncertainty) associated with the motion that occurred between 
 through
through  are noise parameters that, unfortunately, need to be hand-tuned for the particular robot being used. Also,
are noise parameters that, unfortunately, need to be hand-tuned for the particular robot being used. Also,  is in control space and we need to map it into state space. To do this we need the Jacobian of the motion model with respect to the motion parameters
is in control space and we need to map it into state space. To do this we need the Jacobian of the motion model with respect to the motion parameters 
 . To get the complete updated covariance
. To get the complete updated covariance 
 and it is calculated using the measurement model
and it is calculated using the measurement model  .
.

 ,
,  , and
, and  are the x position, y position, and ID of landmark
are the x position, y position, and ID of landmark 
 is a constant for all measurements. It is a
is a constant for all measurements. It is a  diagonal matrix with noise parameters
diagonal matrix with noise parameters  ,
,  , and
, and  . The sigmas represent the noise for landmark range, bearing, and noise, respectively. Like the alphas in equation (3), the sigmas must be hand-tuned in order to obtain good performance.
. The sigmas represent the noise for landmark range, bearing, and noise, respectively. Like the alphas in equation (3), the sigmas must be hand-tuned in order to obtain good performance.
 is then used to calculate the Kalman gain,
is then used to calculate the Kalman gain,  . The Kalman gain determines how heavily the sensor information should be weighted when correcting the estimated new pose
. The Kalman gain determines how heavily the sensor information should be weighted when correcting the estimated new pose 


 (calculated in equation (7) and the actual measurement
(calculated in equation (7) and the actual measurement  and
and  . The measurement probability is also calculated here but we are not making use of this value.
. The measurement probability is also calculated here but we are not making use of this value.


{kind=link}