
This tutorial is part of a series on Simultaneous Localization and Mapping (SLAM) using the extended Kalman filter. See the following for other tutorials in the series:
- Introduction
- Step 0: Introducing the Dataset
- Step 2: Localization With Unknown Correlation
- Step 3: SLAM With Known Correlation
- Step 4: SLAM With Unknown Correlation
In this tutorial I’ll focus on one of the easiest state estimation problems: localization with known measurement correspondence. The “localization” part means that the robot already knows the positions of all of the landmarks in the environment. The “known correspondence” part means that when the robot measures the range and bearing to a landmark it always knows which landmark it’s measuring.
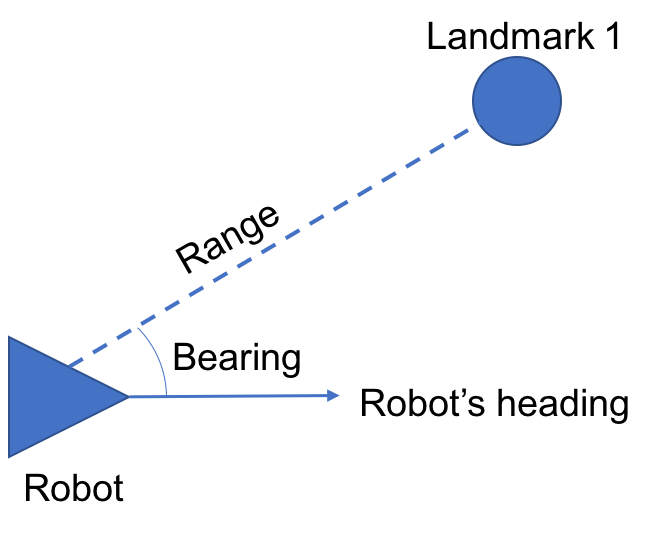{kind=link}
In this tutorial I’ll explain the EKF algorithm and then demonstrate how it can be implemented using the UTIAS dataset. I’ll break it down into the following sections:
Intro To The Algorithm
First off, why do we need this complicated algorithm for localization? Can’t we just track our position with odometry? This isn’t possible because a robot’s pose over time is not deterministic; it can’t be calculated exactly due to errors (also referred to as noise) in the odometry which accumulate over time.
This is why the Kalman filter represents the robot’s pose at time  as a multivariate normal probability distribution with a mean at
as a multivariate normal probability distribution with a mean at  and covariance of
and covariance of  . The robot’s expected (or most likely) pose is at and the uncertainty of that pose is quantified by . The Kalman filter updates the robot’s pose using the robot’s motion from odometry
. The robot’s expected (or most likely) pose is at and the uncertainty of that pose is quantified by . The Kalman filter updates the robot’s pose using the robot’s motion from odometry  . Then it corrects for noise in the motion update using the robot’s sensor readings
. Then it corrects for noise in the motion update using the robot’s sensor readings  .
.
One important advantage of the Kalman filter (and other similar algorithms) is that it is recursive. It only requires information about the state of the robot at time  in order to estimate the state at time . In other words, it doesn’t require information about any of the prior states of the robot from time
in order to estimate the state at time . In other words, it doesn’t require information about any of the prior states of the robot from time  to time
to time  . This means it requires less memory and processor time to compute!
. This means it requires less memory and processor time to compute!
Below I present a mathematical definition for the extended Kalman filter. Most of it is taken from table 7.2 of Probabilistic Robotics by Thrun, Fox, and Burgard. It will be helpful to follow along in Probabilistic Robotics in addition to this tutorial. I’d also recommend reading chapter 3 of that book to gain a better understanding of Gaussian filters and recursive estimation.
Inputs
- the mean of the pose estimate from the previous timestep:

 is the robot’s previous x position in meters
is the robot’s previous x position in meters is the robot’s previous y position in meters
is the robot’s previous y position in meters is the robot’s previous heading in radians
is the robot’s previous heading in radians
- the covariance matrix of the previous timestep,

- this represents the uncertainty of the pose estimate
- the control inputs (or odometry) at the current timestep,

 is the robot’s linear velocity in meters/sec
is the robot’s linear velocity in meters/sec is the robot’s angular velocity in radians/sec
is the robot’s angular velocity in radians/sec
- the measurements from the current timestep,
 where
where  is the number of measurements at time
is the number of measurements at time
- each
 where
where
 is the range to landmark
is the range to landmark  in meters
in meters is the bearing to landmark in radians
is the bearing to landmark in radians is the ID of landmark
is the ID of landmark
- each
 is the correspondence between the measurement and landmarks
is the correspondence between the measurement and landmarks
- for our purposes this will be ignored for now
- the map
 where
where  is the number of landmarks
is the number of landmarks
- each
 where
where
 is the x position of landmark in meters
is the x position of landmark in meters is the y position of landmark in meters
is the y position of landmark in meters is the ID of landmark
is the ID of landmark
- each
Outputs
- the updated pose estimate,
- the updated covariance matrix,
- the measurement probability,
 , which is the likelihood of the measurements given the robot’s estimated pose before measurements were incorporated:
, which is the likelihood of the measurements given the robot’s estimated pose before measurements were incorporated: 
- We’ll be ignoring this for now as well
Algorithm



Motion Update
The algorithm is divided into two parts: the motion update and the sensor update. First, in the motion update the odometry information is incorporated into the state estimate. The motion update is based around a motion model  , which calculates a new pose based on the previous pose and the odometry .
, which calculates a new pose based on the previous pose and the odometry .
(1) 
In this equation denotes the estimated updated mean of the pose distribution. The motion model I’m using assumes that the robot rotates in place, then drives in a straight line, then rotates in place again. This is a common approximation and it’s accurate enough as long as  is small.
is small.
In addition to calculating a new mean for our robot’s pose distribution we need calculate an estimated covariance for the new pose,  . In order to do this we need to multiply the covariance from the last timestep, by the derivative (also called the Jacobian) of the motion model with respect to the previous state :
. In order to do this we need to multiply the covariance from the last timestep, by the derivative (also called the Jacobian) of the motion model with respect to the previous state :
(2) 
The multiplication looks like the following:  . We also need to calculate the additional noise (or uncertainty) associated with the motion that occurred between and .
. We also need to calculate the additional noise (or uncertainty) associated with the motion that occurred between and .
(3) 
The alphas  through
through  are noise parameters that, unfortunately, need to be hand-tuned for the particular robot being used. Also,
are noise parameters that, unfortunately, need to be hand-tuned for the particular robot being used. Also,  is in control space and we need to map it into state space. To do this we need the Jacobian of the motion model with respect to the motion parameters :
is in control space and we need to map it into state space. To do this we need the Jacobian of the motion model with respect to the motion parameters :
(4) 
So we can map the noise to state space with the following multiplication:  . To get the complete updated covariance we add the transformed covariance from the previous timestep to the additional noise:
. To get the complete updated covariance we add the transformed covariance from the previous timestep to the additional noise:
(5) 
So the motion update step updates the robot’s pose mean and covariance based on its odometry. You may have noticed, however, that the covariance only gets larger in this step. This means our uncertainty about the robot’s pose always grows when we incorporate odometry. We can decrease the uncertainty by incorporating sensor information, which is what we do in the next step.
Note: The motion model and associated Jacobians presented in the preceding section are different from those presented in Probabilistic Robotics. The model presented in Probabilistic Robotics assumes that the robot is always moving in an arc and its angular velocity, , is never zero. The Jacobians for this model involve dividing by . This means that the model breaks if is ever equal to zero. This is a problem for us because often is equal to zero in the UTIAS dataset. That is why I subbed in my own motion model.
Sensor Update
The sensor update refines the robot’s pose estimate and decreases its uncertainty. This happens in the for loop of the algorithm. It is run for every measurement that occurs at timestep .
In the first step of the sensor update we calculate what the range and bearing to the landmark would have been if the estimated pose mean were correct. This is called the expected measurement  and it is calculated using the measurement model
and it is calculated using the measurement model  .
.
(6) 
(7) 
Remember that  ,
,  , and
, and  are the x position, y position, and ID of landmark
are the x position, y position, and ID of landmark  , respectively.
, respectively.
We also need to calculate the additional noise associated with the measurement. To do this we need the Jacobian of the measurement model with respect to the robot’s pose:
(8) 
The measurement noise is calculated by multiplying the prior estimated covariance with the measurement model Jacobian and adding additional noise for the new measurement. The additional noise  is a constant for all measurements. It is a
is a constant for all measurements. It is a  diagonal matrix with noise parameters
diagonal matrix with noise parameters  ,
,  , and
, and  . The sigmas represent the noise for landmark range, bearing, and noise, respectively. Like the alphas in equation (3), the sigmas must be hand-tuned in order to obtain good performance.
. The sigmas represent the noise for landmark range, bearing, and noise, respectively. Like the alphas in equation (3), the sigmas must be hand-tuned in order to obtain good performance.
(9) 
 is then used to calculate the Kalman gain,
is then used to calculate the Kalman gain,  . The Kalman gain determines how heavily the sensor information should be weighted when correcting the estimated new pose and .
. The Kalman gain determines how heavily the sensor information should be weighted when correcting the estimated new pose and .
(10) 
The Kalman gain is used to update the estimated pose mean and covariance and as follows:
(11) 
(12) 
The amount of correction to the estimated pose mean depends on and the difference between the expected measurement  (calculated in equation (7) and the actual measurement
(calculated in equation (7) and the actual measurement  . A larger discrepancy between the expected and actual measurement will result in a larger correction.
. A larger discrepancy between the expected and actual measurement will result in a larger correction.
After the sensor update is complete the pose mean and covariance are updated with the estimated values:  and
and  . The measurement probability is also calculated here but we are not making use of this value.
. The measurement probability is also calculated here but we are not making use of this value.
Code
When writing robotics software I’m often frustrated by the separation between theory and software engineering. There are many good theoretical explanations of the extended Kalman filter online. There are also several good examples of code that uses an EKF. But I was unable to find any textbook, academic paper, blog post, or stackexchange thread that did a good job of demonstrating how the math translates into code. I’m hoping my code below will change that. I’ve been careful to explain all major steps and refer to the equations above in the comments. I hope you find it helpful!
Lastly, note that comments in MATLAB begin with a % symbol. The code rendering plugin I used doesn’t seem to get this when highlighting the code, however. So be aware that the highlighting below isn’t always accurate, but the actual code is.
addpath ../common; % adds support functions used in all my EKF programs
% check my github for details
deltaT = .02;
alphas = [.2 .03 .09 .08 0 0]; % robot-dependent motion noise parameters
% see equation 3
% robot-dependent sensor noise parameters
% see equation 9
sigma_range = 2;
sigma_bearing = 3;
sigma_id = 1;
Q_t = [sigma_range^2 0 0;
0 sigma_bearing^2 0;
0 0 sigma_id^2];
measurement_prob = 0;
n_robots = 1;
robot_num = 1;
% load and resample raw data from UTIAS data set
% The robot's position groundtruth, odometry, and measurements
% are stored in Robots
[Barcodes, Landmark_Groundtruth, Robots] = loadMRCLAMdataSet(n_robots);
[Robots, timesteps] = sampleMRCLAMdataSet(Robots, deltaT);
% add pose estimate matrix to Robots
% data will be added to this as the program runs
Robots{robot_num}.Est = zeros(size(Robots{robot_num}.G,1), 4);
% initialize time, and pose estimate
start = 600; % start index is set to 600 because earlier data was
% found to cause problems
t = Robots{robot_num}.G(start, 1); % set start time
% set starting pose mean to pose groundtruth at start time
poseMean = [Robots{robot_num}.G(start,2);
Robots{robot_num}.G(start,3);
Robots{robot_num}.G(start,4)];
poseCov = [0.01 0.01 0.01;
0.01 0.01 0.01;
0.01 0.01 0.01];
% tracks which measurement is next received
measurementIndex = 1;
% set up map between barcodes and landmark IDs
codeDict = containers.Map(Barcodes(:,2),Barcodes(:,1));
% advance measurement index until the next measurement time
% is greater than the starting time
while (Robots{robot_num}.M(measurementIndex, 1) < t - .05)
measurementIndex = measurementIndex + 1;
end
% loop through all odometry and measurement samples
% updating the robot's pose estimate with each step
% reference table 7.2 in Probabilistic Robotics
for i = start:size(Robots{robot_num}.G, 1)
theta = poseMean(3, 1);
% update time
t = Robots{robot_num}.G(i, 1);
% update movement vector per equation 1
u_t = [Robots{robot_num}.O(i, 2); Robots{robot_num}.O(i, 3)];
rot = deltaT * u_t(2);
halfRot = rot / 2;
trans = u_t(1) * deltaT;
% calculate the movement Jacobian per equation 2
G_t = [1 0 trans * -sin(theta + halfRot);
0 1 trans * cos(theta + halfRot);
0 0 1];
% calculate motion covariance in control space per equation 3
M_t = [(alphas(1) * abs(u_t(1)) + alphas(2) * abs(u_t(2)))^2 0;
0 (alphas(3) * abs(u_t(1)) + alphas(4) * abs(u_t(2)))^2];
% calculate Jacobian to transform motion covariance to state space
% per equation 4
V_t = [cos(theta + halfRot) -0.5 * sin(theta + halfRot);
sin(theta + halfRot) 0.5 * cos(theta + halfRot);
0 1];
% calculate pose update
poseUpdate = [trans * cos(theta + halfRot);
trans * sin(theta + halfRot);
rot];
% calculate estimated pose mean per equation 1
poseMeanBar = poseMean + poseUpdate;
% calculate estimated pose covariance per equation 5
poseCovBar = G_t * poseCov * G_t' + V_t * M_t * V_t';
% get measurements for the current timestep, if any exist
[z, measurementIndex] = getObservations(Robots, robot_num, t, measurementIndex, codeDict);
% create two matrices for expected measurement and measurement
% covariance
S = zeros(size(z,2),3,3);
zHat = zeros(3, size(z,2));
% if any measurements are available
if z(3,1) > 1
for k = 1:size(z, 2) % loop over every measurement
j = z(3,k);
% get coordinates of the measured landmark
m = Landmark_Groundtruth(j, 2:3);
% compute the expected measurement per equations 6 and 7
xDist = m(1) - poseMeanBar(1);
yDist = m(2) - poseMeanBar(2);
q = xDist^2 + yDist^2;
% constrains expected bearing to between 0 and 2*pi
pred_bear = conBear(atan2(yDist, xDist) - poseMeanBar(3));
zHat(:,k) = [sqrt(q);
pred_bear;
j];
% calculate Jacobian of the measurement model per equation 8
H = [(-1 * (xDist / sqrt(q))) (-1 * (yDist / sqrt(q))) 0;
(yDist / q) (-1 * (xDist / q)) -1;
0 0 0];
% compute S per equation 9
S(k,:,:) = H * poseCovBar * H' + Q_t;
% compute Kalman gain per equation 10
K = poseCov * H' * inv(squeeze(S(k,:,:)));
% update pose mean and covariance estimates
% per equations 11 and 12
poseMeanBar = poseMeanBar + K * (z(:,k) - zHat(:,k));
poseCovBar = (eye(3) - (K * H)) * poseCovBar;
end
end
% update pose mean and covariance
% constrains heading to between 0 and 2*pi
poseMean = poseMeanBar;
poseMean(3) = conBear(poseMean(3));
poseCov = poseCovBar;
% add pose mean to estimated position vector
Robots{robot_num}.Est(i,:) = [t poseMean(1) poseMean(2) poseMean(3)];
% calculate error between mean pose and groundtruth
% for testing only
%{
groundtruth = [Robots{robot_num}.G(i, 2);
Robots{robot_num}.G(i, 3);
Robots{robot_num}.G(i, 4)];
error = groundtruth - poseMean;
%}
end
% display results!
animateMRCLAMdataSet(Robots, Landmark_Groundtruth, timesteps, deltaT);
Note: My tuning of the noise parameters in the code below is workable. But I didn’t spend as much time on them as I did for subsequent iterations of this tutorial. If you’d like to play with them I’m sure you can improve on my tunings!